

* 이 글은 홍콩과기대 김성훈 교수님의 무료 동영상 강좌 "모두를 위한 머신러닝과 딥러닝 강의"를 보고 요점을 정리한 글 입니다.
Learning Rate(학습율)

Machine Learning(기계 학습)에서 학습을 할때, Cost Function(비용 함수)의 최소지점을 찾기 위하여 Gradient Descent Algorithm(기울기 감소 알고리즘)을 많이 사용합니다. 이 Gradient Descent Algorithm의 공식인 Equation (1)을 보면 Cost Function의 미분값에 Alpha를 곱한것을 볼 수 있습니다. 여기서 이 Alpha가 바로 Learning Rate(학습율)를 의미합니다.
| $$ W := W - \alpha \frac{\partial}{\partial W} cost(W) $$ | (1) |
이 Learning Rate는 적절한 수준의 값을 정하는 것이 매우 중요합니다. 왜냐하면 학습을 할때 만약 Learning Rate가 너무 크게 잡혀있는 경우 Cost Function의 최소지점을 찾지 못하고 점점 이상한 방향으로 학습을 하는 Over Shooting의 경우가 생길수 있고, 만약 Learning Rate가 너무 작게 잡혀있는 경우 Cost Function의 최소지점을 찾기까지의 학습단계가 너무 많이 필요한 경우가 생길 수 있기 때문입니다.
Learning Rate를 정하는것은 정해진 공식이 따로 없습니다. Learning Rate는 환경에 따라서 적합한 값이 달라지기 때문에 직접 계산해보며 조절해야만 합니다. 일반적으로 Learning Rate는 0.01으로 많이 설정하는데, 이 값으로 먼저 학습을 해본 후 결과가 발산한다면 보다 작은 값을, 학습하는데 너무 많은 시간이 소요된다면 큰값을 설정해 주어야 합니다.
Data Preprocessing(데이터 전처리)

Learning Rate를 적절하게 설정해준것 같은데 학습을 해보면 좋지 않은 결과가 나오는 경우가 있습니다. 이런 경우는 데이터에 조금 문제가 있을 때 발생할 수 있습니다. 이럴때 우리는 Data Preprocessing(데이터 전처리)를 해주어야 합니다.
Data Preprocessing에는 몇가지 방법이 있는데, Normalization은 원래의 데이터 분포의 중심을 (0,0)으로 이동시킨 후 값의 분포를 0과 1사이의 범위 이내로 들어가도록 만드는 척도법을 의미하고, Standardization은 평균,분산,표준편차를 이용하여 데이터를 Normalize하는 방법을 의미합니다.
Overfitting(과적합)
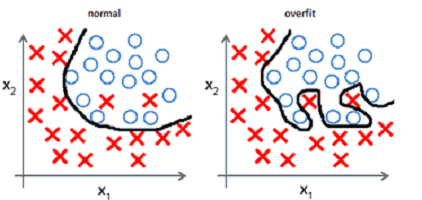
Overfitting(과적합)은 Machine Learning에서의 가장 큰 문제들 중 하나입니다. Overfitting은 말 그대로 Training Data Set에 너무 적합해진 현상을 의미합니다. Training Data Set으로 입력데이터를 집어넣으면 잘 나오지만 그밖의 데이터를 입력데이터로하여 집어넣으면 잘못된 결과가 나오게되는 것이 이 Overfitting의 문제점이라고 할 수 있습니다.
이 Overfitting을 줄이는 방법들에는 여러가지가 있습니다. 가장 좋은 방법은 더 많은 Training Data Set으로 학습을 하는 것입니다. 그 밖의 방법으로는 변수의 수를 줄이는것과 Regularization(일반화)하는 방법등이 있습니다.
Regularization(일반화)

Regularization(일반화)은 데이터를 표현하는 모델을 최대한 덜 울퉁불퉁하게 표현하는 것을 의미합니다. 이러한 Regularization을 수식으로 표현하면 Equation (2)와 같습니다.
| $$ \mathcal{L} = \frac{1}{N} \sum D(S(Wx_i + b), L_i) + \lambda \sum w^2 $$ | (2) |
여기서 Lamda는 Regularization Strength를 의미하는데 이 값을 0으로 설정하면 Regularization을 하지 않겠다는 의미이고 1으로 설정하면 Regularization을 많이 적용한다는 의미입니다. 이 값은 상황에 따라서 적당하게 설정해주면 되는 값입니다.
'강의 Study > 모두를 위한 머신러닝과 딥러닝 강의-시즌 1' 카테고리의 다른 글
| [시즌1].Lecture 08_1 - 딥러닝의 기본 개념과, 문제, 그리고 해결_딥러닝의 기본 개념: 시작과 XOR 문제 (0) | 2024.06.27 |
|---|---|
| [시즌1].Lecture 07_2 - ML의 실용과 몇가지 팁_Training/Testing Data Set (0) | 2024.06.26 |
| [시즌1].Lecture 06_2 - Softmax Regression_Cost Function 소개 (0) | 2024.06.24 |
| [시즌1].Lecture 06_1 - Softmax Regression_Multinomial 개념 소개 (0) | 2024.06.23 |
| [시즌1].Lecture 05_2 - Logistic Classification_Cost Function 소개 (0) | 2024.06.22 |