

* 이 글은 홍콩과기대 김성훈 교수님의 무료 동영상 강좌 "모두를 위한 머신러닝과 딥러닝 강의"를 보고 요점을 정리한 글 입니다.
Dropout
Machine Learning(기계 학습)의 가장 중요한 문제점들 중 하나는 바로 Overfitting(과적합)입니다. 이 Overfitting은 Training Data Set에 너무 적합해진 현상을 의미합니다. Training Data Set으로 입력데이터를 집어넣으면 결과는 잘 나오지만 그밖의 데이터 Test Data Set을 입력데이터로하여 집어넣으면 좋지 않은 결과가 나오게되는 것이 이 Overfitting의 문제점이라고 할 수 있습니다.
Error율과 Neural Network의 Layer수를 비교해 보면 Training Data Set을 입력데이터로 한 결과는 Layer의 수가 많으면 많을 수록 Error율이 지속적으로 감소됩니다. 하지만 Test Data Set의 경우에는 Layer수가 많아지면 Error율이 감소하다가 일정 지점을 넘어서면 다시 증가하는 경향을 보입니다. 이런 Error율이 증가하는 지점의 Layer수보다 Neural Network의 Layer가 많으면 Overfitting이라고 볼 수 있습니다.
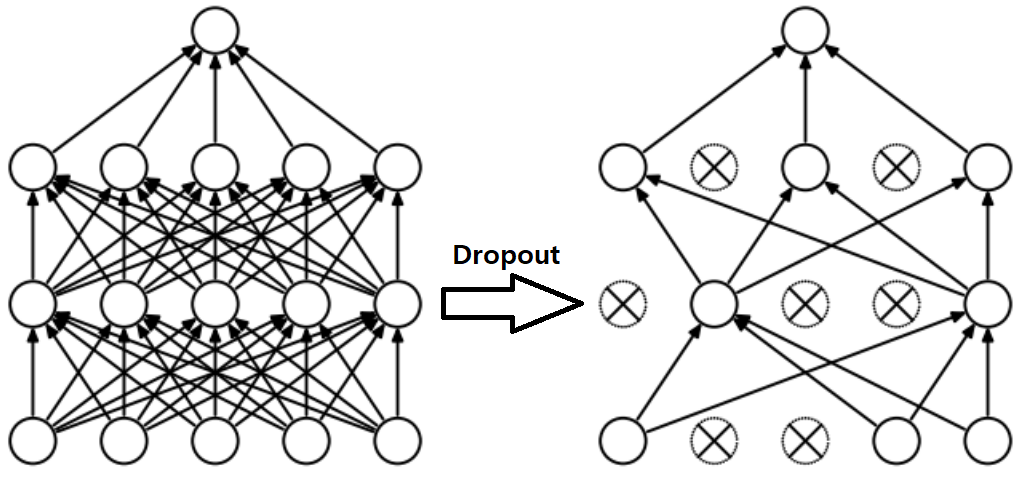
일반적으로 Overfitting을 해결하는 방법은 더 많은 Training Data Set으로 학습을 하거나 변수의 수를 줄이는 방법 그리고 Regularization(일반화)를 하는 방법등 이 있습니다. 하지만 Neural Network에서는 Overfitting을 해결하는 방법으로 Dropout이라는 방법을 사용할 수 있습니다. 이 Dropout 방법은 글자의 의미 그대로 학습할 때 전체 Neural Network에서 임의의 노드 몇개를 참여시키지 않는 방법을 의미합니다.
Training Data Set을 사용하여 1번 학습을 할 때 임의의 노드 몇개를 제외한 후 학습을 하고 그 다음번 학습에서는 또 다른 임의의 노드 몇개를 제외한 후 학습을 합니다. 이런 방법을 학습하는 동안 반복한 후 마지막 Test Data Set을 사용할 때에는 모든 노드를 사용하여 결과를 확인하는 방법이 이 Dropout 방법인데 상당히 좋은 효과를 볼 수 있는 방법입니다.
Ensemble Model(앙상블 모델)
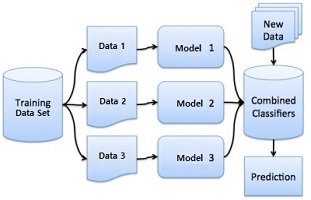
Ensemble Model(앙상블 모델)이란 Training Data Set이 많고 학습시킬 수 있는 기계가 많을 때 사용할 수 있는 방법으로 같은 형태의 Neural Network 모델 여러개를 만든 후 Training Data Set에서 가져올 수 있는 Data를 집어넣어서 학습을 시킵니다. 각 데이터를 사용해서 학습하는 모델은 초기값을 다르게 설정해주므로 나오는 결과 또한 다르게 나올 것 입니다. 이렇게 나온 서로 다른 결과들을 하나로 합쳐서 하나의 결론을 만든 후 이것을 사용해서 Test Data Set에 적용시키는 모델을 Ensemble Model 이라고 합니다.
Ensemble Model은 일반적으로 학습 모델을 사용하는 것 보다 2~5% 성능이 향상되는 굉장히 좋은 모델이라고 할 수 있습니다.