

* 이 글은 홍콩과기대 김성훈 교수님의 무료 동영상 강좌 "모두를 위한 머신러닝과 딥러닝 강의"를 보고 요점을 정리한 글 입니다.
LeNet-5

LeCun 교수님은 1990년에 LeNet-1을 발표하였고 이것을 조금씩 보완해서 1998년에 LeNet-5를 만들어 내었습니다.
LeNet-5에서는 입력데이터의 크기를 32 x 32로 만들었고 Convolution Layer에서 사용되는 Filter의 크기를 5 x 5로 Stride는 1으로, Pooling Layer에서 사용되는 Filter의 크기를 2 x 2로 Stride는 2로 설정하였습니다.
AlexNet
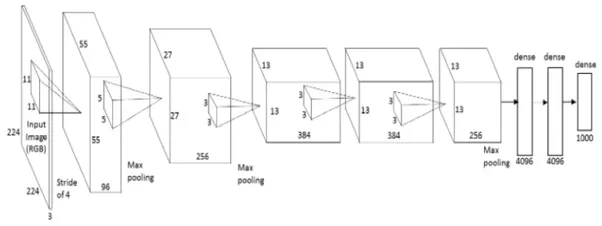
Alex는 2012년에 AlexNet을 논문으로 발표하였습니다. AlexNet은 2개의 병렬구조인 점을 제외하면 LeNet-5와 크게 다르지는 않습니다. 하지만 모든 Convolution Layer에서 사용하는 Filter의 크기와 Stride를 통일한 LeNet-5와 달리 AlexNet은 첫번째 Convolution Layer에서는 Filter의 크기를 11 x 11로 Stride는 4로 설정, 두번째 Convolution Layer는 Filter의 크기를 5 x 5로 Stride는 1으로 설정, 나머지 Convolution Layer에서는 Filter의 크기를 3 x 3으로 Stride는 1으로 설정하였습니다. 그리고 모든 Pooling Layer에서 사용하는 Filter는 3 x 3로 Stride는 2로 설정하였습니다.
AlexNet에서는 처음으로 ReLU함수가 사용되었으며 DropOut기법이 사용되었습니다. 또한 이 AlexNet을 Ensemble Model에 적용시키면 더 좋은 성능을 얻을 수 있었습니다.
GoogLeNet

GoogLeNet은 2014년에 구글에 의해서 발표되었습니다. 이전까지의 CNN의 Layer의 개수가 10개 미만이었다면 GoogLeNet은 22개의 Layer를 사용함으로써 에러율을 확연히 낮추었습니다.
GoogLeNet에서 가장 중요한 특징은 Inception Module이라는 것입니다. 같은 Layer에 서로 다른 크기를 갖는 여러개의 Convolution 을 벙렬적으로 활용한 Inception Module은 Neural Network를 더 깊게 만들면서도 연산량을 늘리지 않게 해 줍니다.
ResNet

ResNet은 2015년에 He 교수님에 의해서 발표되었습니다. ResNet은 152개의 Layer를 사용하는 Ultra-Deep Model을 가지고 있으면서도 좋능을 보이는데 이것은 Residual Learning이라는 방법을 사용했기 때문입니다. Residual Learning은 2개의 Layer에서 입력과 출력의 차이값을 얻도록 학습하는 방법을 말합니다. 이런 학습 방법을 사용하면 입력에서 출력으로 바로 연결되는 Shortcut 연결이 생기게 되는데 이 Shortcut을 통한 연산량 증가는 없으면서 정확도를 개선할 수 있습니다.